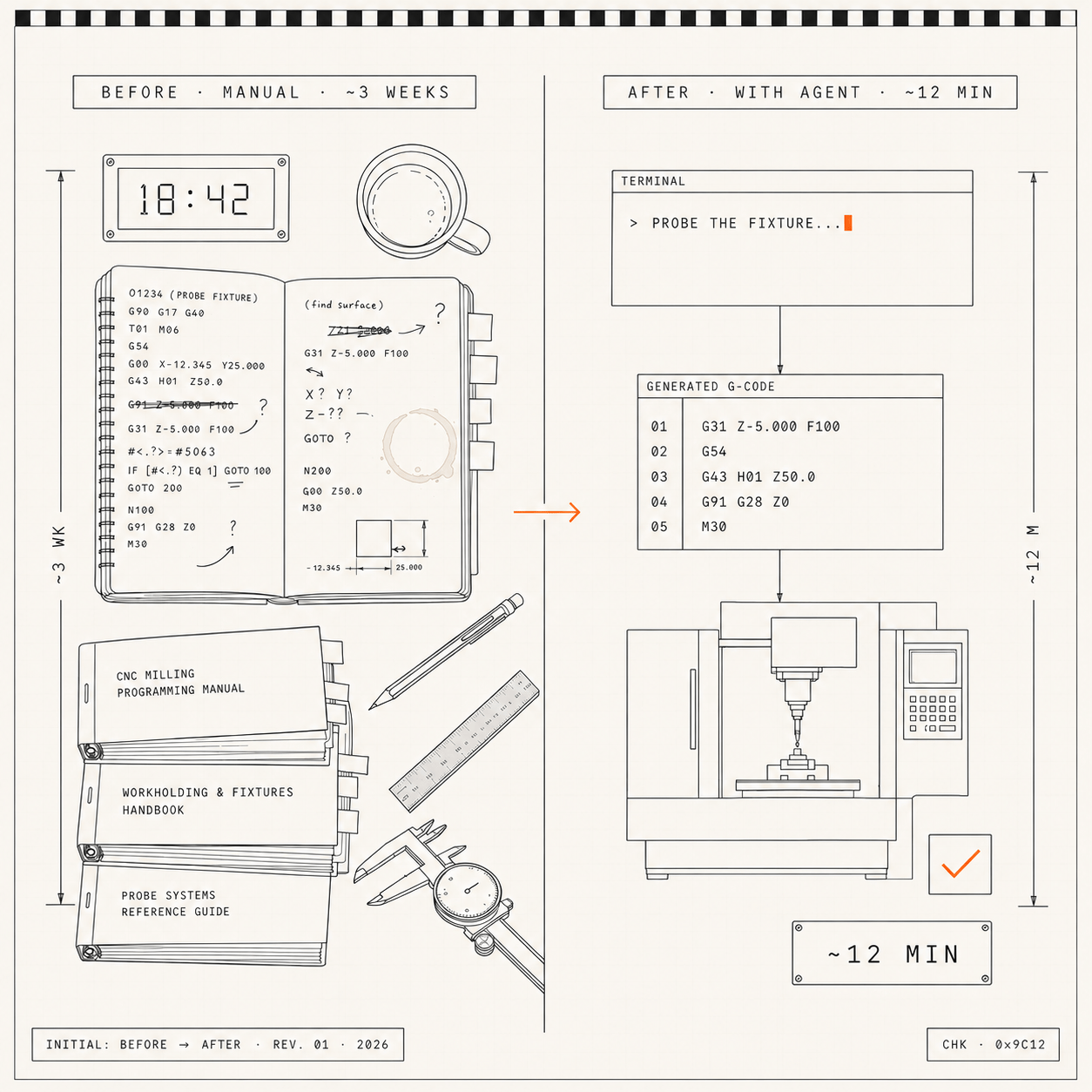
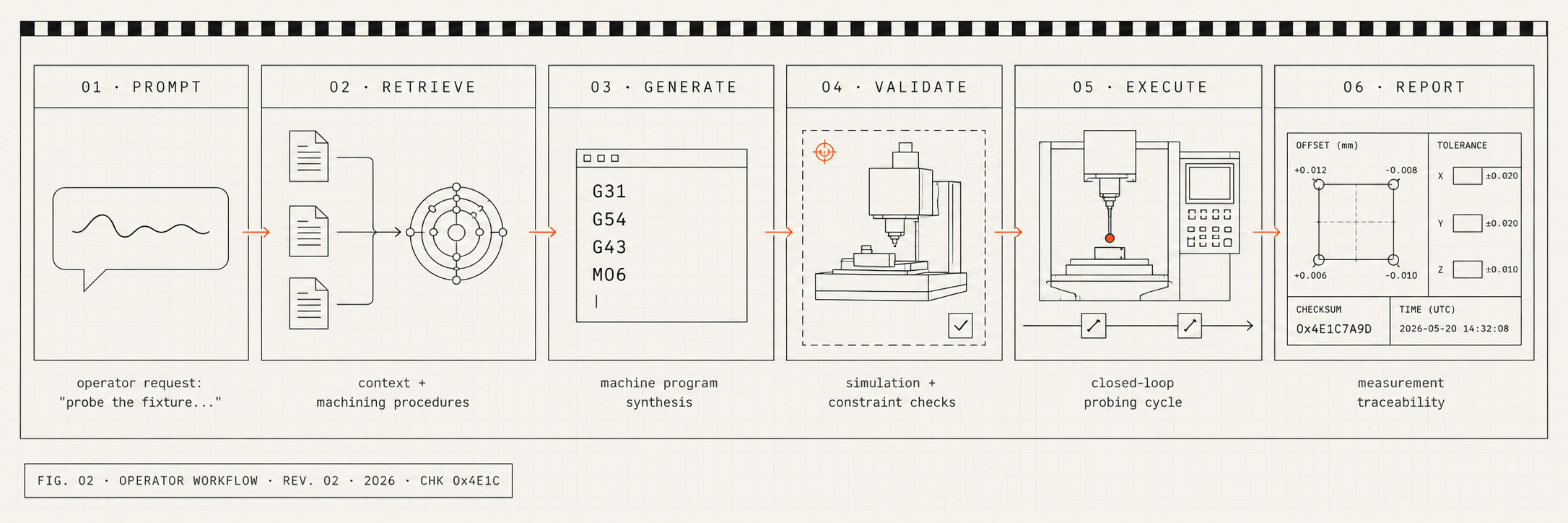
A worked example
From plain English to validated equipment code.
An engineer describes what should happen; the stack writes the code, validates it in a sandbox, executes under two safety gates, and signs the audit log. Below is how it's built — and what one run looks like end to end on a CNC mill.